Trying to further reduce the power consumption from my R720XD.
XOMay 2, 2022
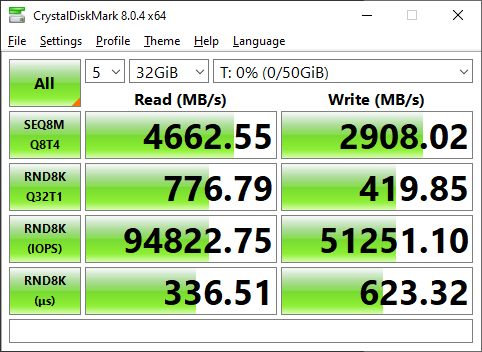

Well, I have been wanting to get infiniband working for a while. I decided today…
XOMarch 26, 2022
A short rant about doing the math to determine which is the most economical decision…
XOJanuary 4, 2022